Lesezeit: 6 Minuten
AWS Lambda: Erste Schritte mit Java
Serverless-Angebote erfreuen sich zurzeit großer Beliebtheit. Amazon hat mit AWS ein breites Spektrum an Diensten, u.a. auch AWS Lambda. In diesem Artikel lernen wir, was die Vorteile bei der Verwendung von AWS Lambda sind und wie wir Java-Code in AWS-Lambda installieren und ausführen können.
Wir verwenden bei der Implementierung Java 17 mit Gradle und Lombok. Den Beispielcode aus diesem Artikel haben wir in einem Git-Repository bereitgestellt. Weiterhin benötigen wir für die Installation und Ausführung einen AWS-Account.
Warum AWS Lambda?
Cloud Computing bietet mit IaaS/CaaS/PaaS/FaaS/SaaS ein breites Spektrum an Diensten. Allen gemeinsam ist die höhere Effizienz und Optimierung durch Auslagern der Verantwortlichkeiten für Elastizität, Skalierbarkeit, Sicherheit, Disaster Recovery und vieles mehr.
Eine weit verbreitete Nutzung besteht in der Implementierung von Microservices-Architekturen mit CaaS bzw. PaaS. Anwendungen werden dabei üblicherweise fachlich geschnitten (Domain Driven Design) und mithilfe von Container-Technologien in der Cloud betrieben. Die Verwendung von Containern ermöglicht eine automatisierte Skalierung, die Kommunikation mit standardisierten Protokollen außerdem auch Flexibilität bei der Auswahl der Technologien für die Implementierung. Jedoch laufen diese Container dauerhaft und erzeugen damit je nach Modell laufende Kosten unabhängig von deren Nutzung. Außerdem verbrauchen Cloud-Systeme mit laufenden Containern mehr Strom, was dem derzeitig aufkommenden Trend zur Minimierung des CO2-Fußabdrucks (Green IT) entgegensteht.
Hier kommt AWS Lambda ins Spiel. Java-Entwickler kennen seit Java 8 bereits die gleichnamigen Lambda Expressions. Und die Namensgleichheit kommt nicht von ungefähr – stehen beide Technologien für eine Ausführung On-Demand. Jedoch betrachten wir bei AWS Lambda die Ausführung von Containern, die dann im Bauch wiederum beliebige Technologien enthalten können. Um dies zu ermöglichen, ist es wichtig, eine standardisierte Aufrufschnittstelle zu definieren und die Startzeiten für Container so performant wie möglich zu gestalten.
AWS Lambda ist außerdem Teil einer Serverless-Familie. Zwar erlaubt es durchaus, eigens konfigurierte Container zu deployen, es bietet aber bereits vordefinierte Laufzeitumgebungen an, aktuell für Java, C#, node.js, Python, Ruby und Go. Damit entfällt das Server-Management, was die Entwicklung effizienter gestaltet und die Anwendungen von Natur aus skalierbar macht. Außerdem sind die Kosten für die Nutzung solcher Angebote im Sinne von „Pay-as-you-go“ geringer als sonst.
Was kann mit AWS Lambda ausgeführt werden?
Wie so oft bietet AWS Lambda ein Werkzeug an, das unterschiedlich genutzt werden kann. Die Bandbreite ergibt sich hierbei durch die Einbettung in die Landschaft an Cloud-Diensten. So kann eine Lambda-Funktion beispielsweise im Rahmen eines Prozess-Flows mit AWS Step Functions aufgerufen werden. Solche Funktionen erledigen dann kleine, abgeschlossene Aufgaben, z.B. den Aufruf eines REST-Service oder einen kleinen Teil an Business-Logik. Bei Einbindung hinter einem API-Gateway ist es allerdings durchaus möglich, komplette Microservices als Lambda-Funktion zu betreiben. Somit können bestehende Anwendungen leicht auf On-Demand-Betrieb migriert werden (Lift and Shift). Spring Boot und Quarkus haben für diesen Anwendungsfall bereits Integrationen. Mittel- und langfristig ist es jedoch empfehlenswert, Lambdas kleinteiliger auf einzelne Funktionen zu schneiden.
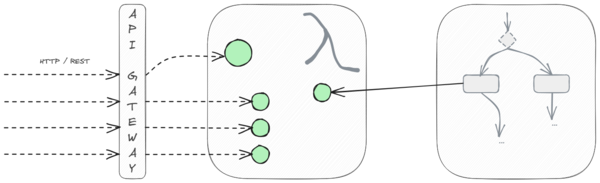
Wie funktioniert ein Aufruf mit AWS Lambda?
JSON
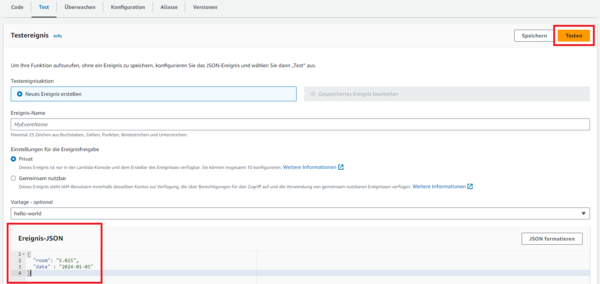
AWS arbeitet mit sogenannten Event-Objekten, die in Form von JSON bei der Kommunikation zwischen den Bausteinen der Gesamtarchitektur übertragen werden. So auch bei Aufruf eines Lambdas – es wird ein JSON-Objekt übergeben und es wird mit einem JSON-Objekt geantwortet. Die Bearbeitung übernimmt dann ein RequestHandler, den wir mit der jeweiligen Logik implementieren.
Während beim Aufruf über Step Functions das JSON-Objekt beliebig definiert werden kann, erhalten wir vom API-Gateway ein vordefiniertes Schema. Ein Beispiel dafür finden wir in der AWS-Dokumentation.
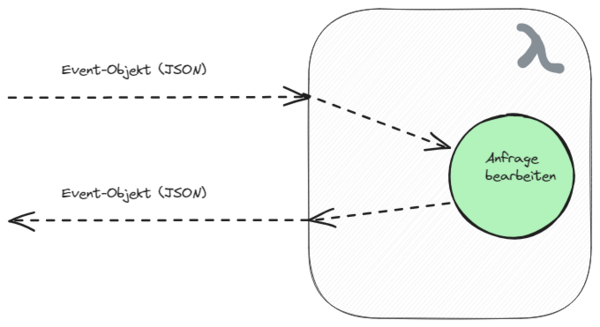
Kalt- vs. Warmstart
Lambdas haben einen Lebenszyklus. Bei der ersten Anfrage wird der Code geladen (aus dem eigenen Speicher bzw. üblicherweise aus einem S3-Bucket) und die Laufzeitumgebung generiert (Kaltstart). Danach erfolgt dann die Ausführung des Codes. Nach der Ausführung wird die Laufzeitumgebung behalten, sodass bei erneuter Anfrage lediglich der Code ausgeführt werden muss (Warmstart). Erfolgt längere Zeit keine Anfrage, wird die Laufzeitumgebung freigegeben. Bei erneuter Anfrage erfolgt dann wieder ein Kaltstart. Details dazu finden wir in einem AWS-eigenen Blogeintrag.
Für die Performance eines Lambdas ist also vor allem die Zeit zur Initialisierung entscheidend. Das gilt einerseits für den Container beim Kaltstart, als auch bei jeder Anfrage für unseren Code. Für die Optimierung des Codes sollten wir vor allem auf minimale Initialisierungen achten, z.B. Lazy Initialization konfigurieren oder unnötige Dependencies vermeiden. Native Builds mit GraalVM verlagern Initialisierungsvorgänge wie Classpath-Scanning, Reflection, Dependency-Injection-Analysen und JIT-Compiling nach vorn in die Bauzeit. In letzter Instanz kann AWS Lambda bereits initialisierte Anwendungen „warm“ halten, was jedoch zusätzliche Kosten verursacht (Provisioned Concurrency).
Wie implementiere ich eine Funktion für AWS Lambda?
Grundsätzlich können wir Lambdas mit beliebigen Programmiersprachen oder als Shell-Skript implementieren. Für Java, C#, node.js, Python, Ruby und Go gibt es bereits fertige, optimierte Laufzeitumgebungen. Wir implementieren unser Beispiel mit Java und verzichten zur Vereinfachung bewusst auf Frameworks wie Spring oder Quarkus.
Beispiel
Als fachliches Beispiel implementieren wir eine Funktion zur Reservierung von Räumen für jeweils einen bestimmten Tag. Hierfür implementieren wir im Kern einen RoomReservationService mit folgender Aufrufschnittstelle:
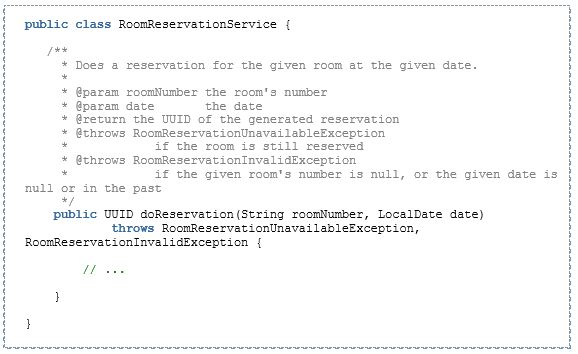
Einstiegspunkt
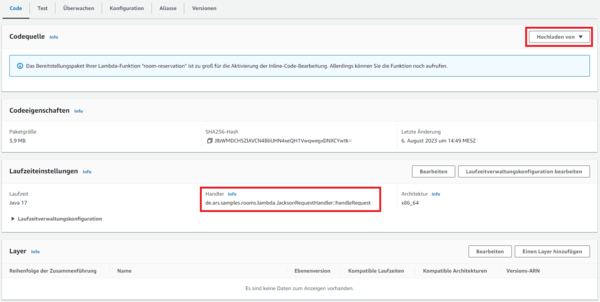
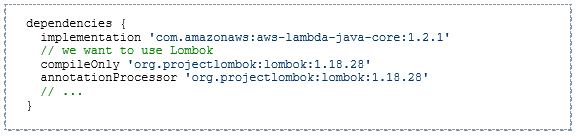
Für die Aufrufschnittstelle kann jede öffentliche Funktion einer beliebigen Klasse definiert werden. Üblich ist jedoch die Implementierung eines in AWS bereitgestellten RequestHandler-Interfaces. Dieses wird vom AWS Lambda SDK bereitgestellt, das wir als Dependency ebenso wie Lombok in unserem Projekt einbinden:
Input
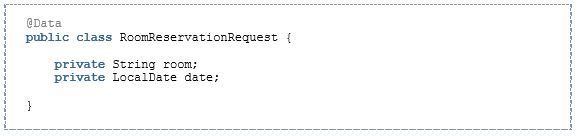
Für die Definition der Aufrufschnittstelle benötigen wir nun einen Datentyp, der von AWS Lambda automatisch auf das Event-Objekt gemappt wird. Der Aufruf für die Raumreservierung soll mit diesem Objekt erfolgen:

Der zugehörige Datentyp sieht dann in etwa so aus:
Output
Und auch für die Antwort des Lambdas benötigen wir einen Datentyp:

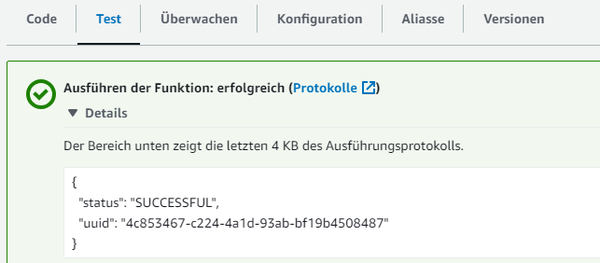
Damit antwortet unser Lambda im Erfolgsfall mit diesem JSON:

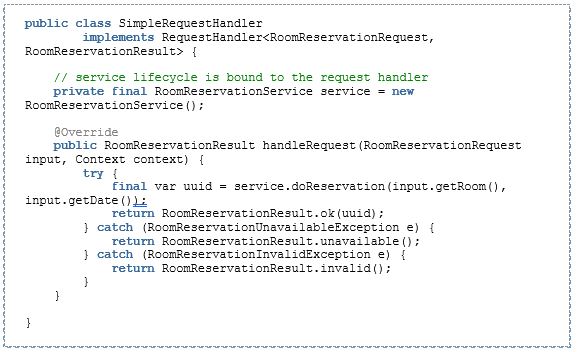
Handler-Implementierung
Die Implementierung des Handlers verbindet dann alle Komponenten miteinander:
JSON-Serialisierung mit Standard-Frameworks
Das Mapping der Objekte auf JSON erfolgt mit einer Eigenimplementierung von AWS. Für eine bessere, standardisierte Konfiguration kann es sinnvoll sein, auf Standard-Frameworks wie Jackson, GSON oder JSON-B zurückzugreifen. Für größer geschnittene Lambdas kann es außerdem erforderlich sein, flexibel auf unterschiedliche Eingangs-JSON reagieren zu können.
Wir möchten in unserem Beispiel auf Jackson umbauen. Dafür binden wir die entsprechenden Dependencies ein:

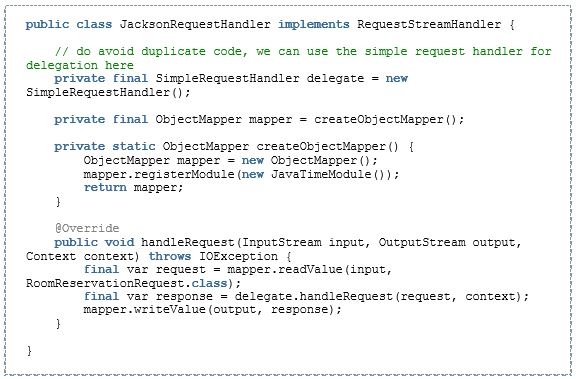
Nun implementieren wir statt dem Request Handler einen RequestStreamHandler, der anstelle von fertigen Objekten mit In- und OutputStream arbeitet. In unserem Beispiel nutzen wir die o.g. Implementierung als Delegate. Damit trennen wir auch automatisch Verantwortlichkeiten:
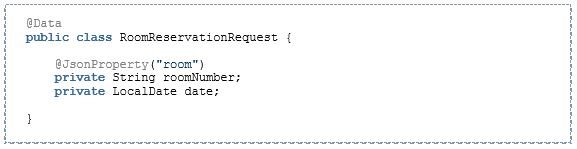
Jetzt haben wir die Möglichkeit, die Jackson-eigenen Konfigurationsmöglichkeiten zu nutzen. Unser Datentyp für das Event-Objekt könnte nun auch so ausschauen:
Logging
AWS Lambda Logging in AWS CloudWatch erfolgt automatisch bei Nutzung der JRE-eigenen System-Klasse oder aber bei Nutzung des über den Context-Parameter mitgelieferten Loggers, der allerdings keine Log-Levels unterscheiden kann:

Eine Integration von Log4j2 kann sinnvoll sein – z.B. um Ausgaben von Dependencies auf Basis von Log4j2 ebenfalls zu erhalten. Hierfür nehmen wir die entsprechende Dependency auf:

Wir konfigurieren Log4j2 wie gewohnt per log4j2.xml. Hierbei ist zu beachten, dass das AWS Lambda SDK einen eigenen Appender bereitstellt, der die AWS Request ID automatisch mitloggen kann, was für Tracing notwendig ist:

Nun können wir in unseren Anwendungsklassen Log4j2-Logger verwenden:

AWS-spezifische Events
Wie bereits erwähnt, können Lambdas auch von anderen Komponenten der AWS-Infrastruktur mit standardisierten Event-Objekten aufgerufen werden. In diesem Fall wäre es mühsam, die entsprechenden Java-Datentypen selbst zu erstellen und zu verwalten. Selbstverständlich bietet AWS diese Datentypen bereits in einer Bibliothek an. Wir erweitern hierfür unser Projekt lediglich um eine weitere Dependency:

Für einen Aufruf vom API-Gateway z.B. können wir den Handler nun so implementieren:
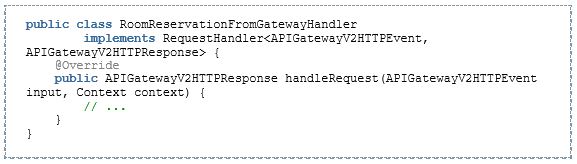
Wie installiere und starte ich die Lambda-Funktion?
Build
Neben dem klassischen JAR erlaubt AWS auch die Bereitstellung einer ZIP-Datei. Dies ermöglicht das Verpacken mitsamt der Abhängigkeiten, ohne sog. Shaded JARs bzw. Uber JARs erzeugen zu müssen. Hierzu erweitern wir unsere Gradle-Konfiguration wie folgt:
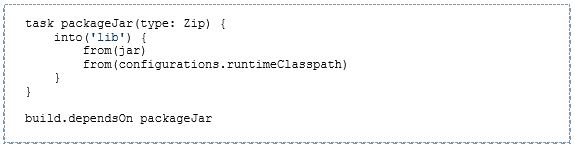
Beim Bauen wird damit ein AWS-Lambda-konformes ZIP erstellt, das alle Abhängigkeiten enthält: